How Datashare Works
Datashare replicates Dune’s processed blockchain data directly into your cloud data warehouse: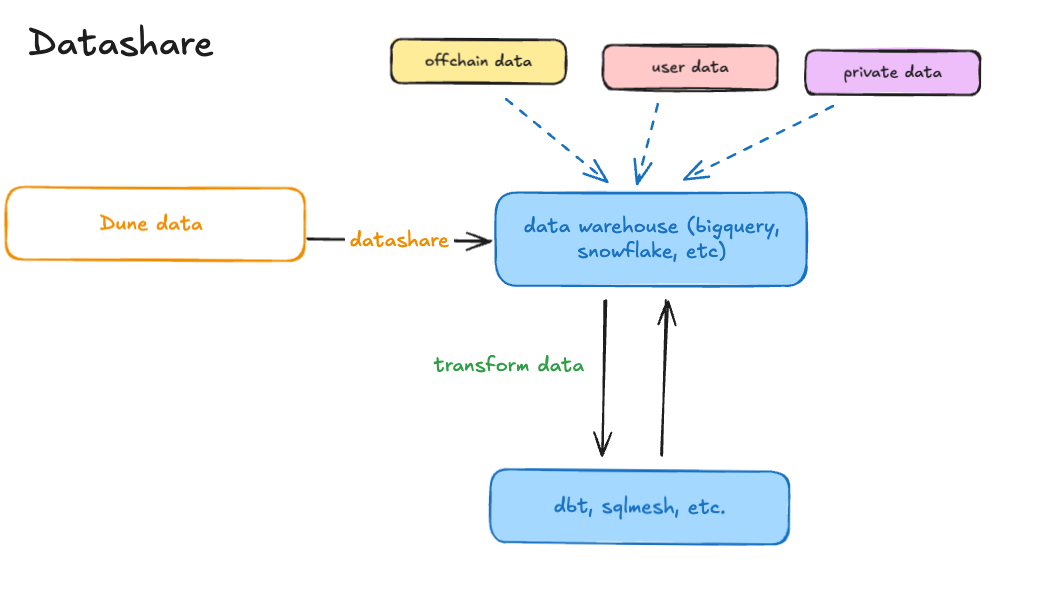
- Data Replication: We maintain live copies of all Dune tables in your Snowflake or BigQuery environment
- Native Integration: Data appears as regular tables/datasets in your warehouse - no APIs or external connections
- Fresh Data: Automatic updates keep your data in sync with Dune’s platform (hourly/daily refresh)
- Your Environment: Query using your warehouse’s native SQL, compute, and security controls
This is the same curated, decoded blockchain data that powers dune.com - optimized for analytics with proper data types and indexing.
Platforms
| Platform | Access Method | Trial Available |
|---|---|---|
| ❄️ Snowflake | Marketplace or Direct Share | 30-day free trial |
| 🔍 BigQuery | Dataset Sharing | Contact for trial |
| 🧱 Databricks | Cross-Region Replication | Contact for trial |
| 🪣 S3 Export | Iceberg tables in a Dune-managed S3 bucket (dbt only) | Contact for setup |
Why Choose Datashare
- Complete Privacy: Query in your warehouse - Dune never sees your queries or results
- Join Your Data: Seamlessly combine blockchain data with your internal datasets
- Cost Control: Use your existing warehouse compute and manage costs directly
- No Rate Limits: Query as much as you need without API constraints
- Enterprise Security: Leverage your warehouse’s existing security and compliance controls
- dbt Integration: Publish dbt-managed transformation outputs from Dune directly into your warehouse with dbt to Datashare
Working with Dune
Getting Started
For Trials:- Snowflake: Self-service via Snowflake Marketplace
- BigQuery: Email datashares-sales@dune.com with your requirements
What We Need From You
To set up datashare access, we need specific identifiers from your cloud environment:Snowflake Requirements
Snowflake Requirements
Please provide your Snowflake data sharing account identifier so I can grant you access to a listing. To find this identifier log in to your Snowflake account and click at your user profile at the bottom of the screen > Account > View account details > Copy data sharing account identifier (you can view a visual path here). You can also run the following SQL command:Then, share your identifier with me.
BigQuery Requirements
BigQuery Requirements
Required Information:
- GCP Project ID (not project name - the unique ID)
- Principal for access (user email, service account, or domain)
- Preferred region (US Central 1 or EU West 2)
- Chains of interest (optional - we can share all by default)
- User:
user:alice@company.com - Service Account:
serviceAccount:etl-service@my-project.iam.gserviceaccount.com - Domain:
domain:company.com(all users in domain)
S3 Export Requirements
S3 Export Requirements
S3 Export is available only through dbt to Datashare. You publish your own dbt-managed tables to a Dune-managed S3 bucket. There is no managed replication of Dune’s full dataset to S3.Required Information:
- Preferred AWS region: where the export bucket is created
- Read access principal: either an IAM role ARN in your AWS account, or your AWS account ID
Setup Process
- Share Identifiers: Provide the required identifiers for your platform
- Access Configuration: We configure sharing permissions on our side
- Verification: We’ll confirm when data is available in your environment
- Support: Ongoing technical support for queries and optimization
Platform-Specific Access
Snowflake Guide
Marketplace access, data types, and query examples
BigQuery Guide
Dataset sharing, principals, and optimization tips
S3 Export Guide
Iceberg tables in a Dune-managed bucket, access, and Requester Pays
dbt to Datashare
Sync dbt-managed tables from your Dune namespace into your warehouse
Next Steps
- Try a free trial - Test our data on your platform
- Review platform guides - Learn about data types and querying
- Contact enterprise team - Discuss production requirements
- Check FAQs - Common questions and troubleshooting