Database Fundamentals
At their core, databases are sophisticated systems designed to store, retrieve, and manage data. Their primary goal is to provide fast, efficient, and reliable access to vast amounts of structured information. You can think of a database as a collection of tables, where each table is a collection of rows and columns. Conceptually, these tables exist in two ways:- Logical: The logical view of a table is the way the data is organized and presented to the user. This is the view you see when you query a table.
- Physical: The physical view of a table is the way the data is stored on disk. This is the view you see when you look at the underlying files that make up the table.
- Data partitioning: Data partitioning is a technique that divides data into smaller chunks called partitions. This reduces the amount of data that needs to be stored and accessed, which improves performance.
- Data indexing: Data indexing is a technique that creates a data structure called an index. This data structure contains information about the data in a table, which allows the database to quickly find the data it needs.
- Data storage layout: Data storage layout relates to how the data is stored on disk. This includes the file format, how the data is physically stored on disk, and how the data is organized in memory. The right data storage layout can significantly improve performance.
- Data compression: Data compression is a technique that reduces the size of data by removing redundant information. This reduces the amount of data that needs to be stored and accessed, which improves performance.
- Data caching: Data caching is a technique that stores frequently accessed data in memory. This reduces the amount of data that needs to be stored and accessed, which improves performance.
DuneSQL Storage Architecture
Dune stores data in Parquet files, which are first and foremost columnar storage files, but also utilize some of the advantages of row-oriented storage. Data in Parquet systems is partitioned by rows into multiple Parquet files, and within each file, the data is further partitioned into row groups. However, the pages inside of row groups store data in columns rather than rows. As a result, the database appears row-oriented at a higher level, but it reads data from column-oriented pages when accessing specific values. Additionally, each Parquet file contains metadata about the data it stores, mainly min/max column statistics for each column. This allows the database to efficiently skip entire Parquet files or row groups within files while scanning through a table, provided that the column contains values that are not random and can be ordered.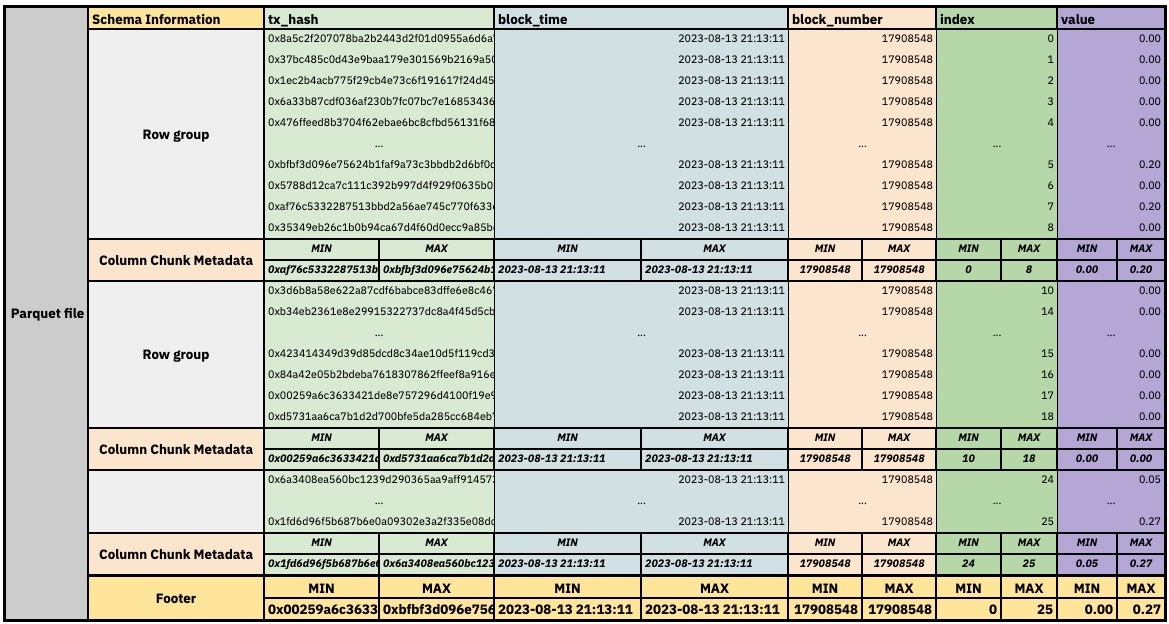
Very simplified contents of a Parquet file
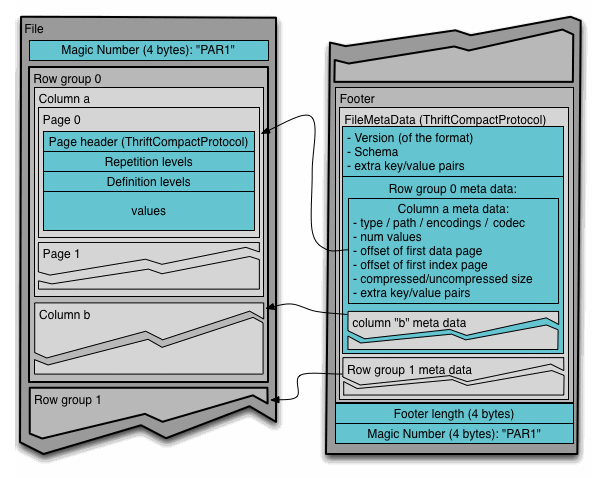
Schematic view of a Parquet file
min/max values of each column are used to efficiently skip entire Parquet files or row groups within files while scanning through a table, provided that the column contains values that are not random and can be ordered. This is a key difference between DuneSQL and other databases like Snowflake.
Query Processing in DuneSQL
If you query a table in DuneSQL, the system will access the data in the following order:- File Level: At the foundational level, the query engine locates the specific Parquet files associated with the table or a portion of the table being queried. It reads the metadata contained in the footer of each Parquet file to determine whether it might contain the data needed for the query. It will skip any files that do not contain the data needed for the query.
- Row Group Level: Once the appropriate Parquet file is identified, the engine will access the relevant row groups within the file, based on the query conditions. Again, it will first read the metadata of each row group to determine whether it might contain the data needed for the query. If the row group does not contain the data needed for the query, it will skip the row group and move on to the next one.
- Column Chunk Level: Once the appropriate row group is identified, the system will access the relevant column chunks within the row group, based on the query conditions. The column chunks contain the actual data that is needed for the query. The database will only read the column chunks that contain the data needed for the query. It will not read the logical row - saving time and resources.
- Page Level: Within the column chunk, the data is further segmented into pages. The database reads these pages into memory, benefiting from any compression or encoding optimizations.
Delta Lake Integration
DuneSQL also leverages Delta Lake for additional data management capabilities. Delta Lake provides:- ACID transactions: Ensures data consistency and reliability
- Schema evolution: Allows tables to evolve over time without breaking existing queries
- Time travel: Enables querying historical versions of data
- Upserts and deletes: Supports more complex data operations than traditional Parquet files
- Data versioning: Maintains a complete history of changes to the data
Time Partitioning
DuneSQL leverages time-based partitioning extensively, as blockchain data is inherently time-ordered. Most tables are partitioned by:- Block time: The timestamp when a block was mined
- Block date: The date component of block time (often more efficient for queries)
- Block number: The sequential number of the block
Columnar Storage Benefits
The columnar storage format provides several key advantages for blockchain data:- Compression: Similar data types in columns compress very well, reducing storage requirements
- Selective column reading: Only the columns needed for a query are read from disk
- Vectorized processing: Operations can be performed on entire columns at once
- Better cache utilization: Related data is stored together, improving memory access patterns
Notable Exceptions
A notable exception to the general rule of using sequentially ordered columns is the Solana datasetaccount_activity, which is ordered by account_keys rather than block_time. This allows for utilizing the min/max values for account_keys when building queries based on raw Solana data.
This architecture makes DuneSQL particularly well-suited for blockchain data analysis, where queries often involve time-based filtering and aggregations across large datasets. The combination of Trino’s distributed query processing, Parquet’s columnar storage, and Delta Lake’s data management provides a robust foundation for handling the scale and complexity of blockchain data.